Cosmos DB Drift: A Terraform Dilemma
We set up a Cosmos DB instance using Terraform, intending to use it as the backend for a suite of microservices running on Azure Functions. Everything was working smoothly, and our transactional systems were happily generating and storing valuable data. As our needs evolved, we wanted to integrate this data into Power BI for analytics and visualization.
To achieve this, we attempted to configure an analytical pipeline by setting up a Synapse workspace through the Azure portal. Since the Synapse workspace was provisioned in a different resource group, we assumed it wouldn’t affect our existing Cosmos DB setup. However, this assumption turned out to be potentially disastrous.
Terraform Drift and the Drop-Create Problem
Upon provisioning the Synapse workspace (a totally different resource in a totally different resource group — mind you), we noticed an unexpected and concerning change: Terraform detected a drift in our Cosmos DB configuration. Specifically, the analytical_storage_ttl attribute was set to -1, a change that seemed harmless but had a massive unintended consequence. The Terraform provider interpreted this drift as a reason to drop and recreate the entire Cosmos DB account.
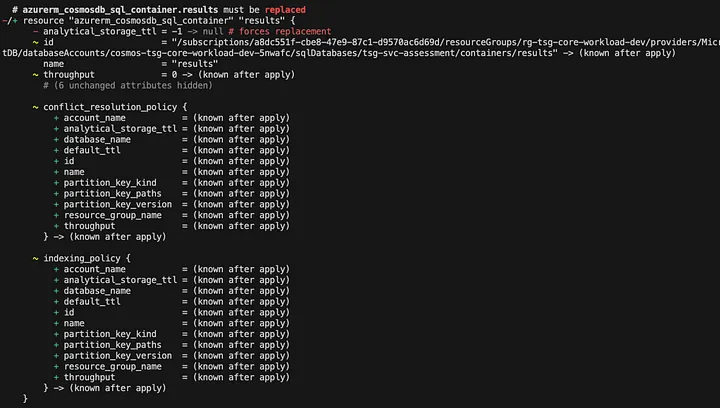
This was a major problem. Destroying and recreating the Cosmos DB account would mean losing all of our production data. Clearly, this was an issue with the Cosmos DB Terraform provider, as modifying the analytical_storage_ttlattribute should not necessitate such a drastic action. We reported this as a bug on GitHub, but in the meantime, we had to find a way to prevent Terraform from taking destructive action.
Avoiding Disaster: Operator Best Practices
This situation underscores why operators must carefully review Terraform plans before applying them. A seemingly innocuous change can have catastrophic consequences if not properly managed. Here are a few key takeaways from this experience:
- Watch out for Azure Portal ClickOps Drift Creation — Be mindful that granting any users, no matter how senior, might inadvertently create drift on your resources managed by Terraform. Ideally, all users should be read-only, relying on automation accounts to enact change.
- Check the Plan Thoroughly — Always review Terraform’s execution plan to ensure that critical resources aren’t being unintentionally destroyed.
- Use Lifecycle Constraints — Adding lifecycle constraints such as ignore_changes can help prevent Terraform from unnecessarily modifying resources due to changes made outside of Terraform.
- Leverage Azure Resource Locks — While not our favorite solution, resource locks can provide an additional layer of protection against accidental deletions or modifications.
Resolving the Drift Without Destroying Data
Faced with this issue, we had to find a way to resolve the drift without losing our data. The best approach in this case was to update our Terraform code to reflect the new value (-1) that had been introduced as drift. By explicitly setting this value in our Terraform configuration, we ensured that Terraform no longer saw it as an unexpected change, preventing the unnecessary drop-create operation.
Conclusion
Terraform is an incredibly powerful tool for infrastructure as code, but it requires careful management to prevent unintended consequences.
Drift detection is a valuable feature, but when changes are introduced outside of Terraform — especially by Azure’s own services — it can lead to dangerous situations. By staying vigilant, reviewing plans, and making strategic updates to our configurations, we can maintain control over our infrastructure while avoiding unnecessary downtime and data loss.