OpenAI RAG Cost Breakdown and Reflections
Standing up a Retrieval-Augmented Generation (RAG) environment using Azure services was both enlightening and expensive. I followed the “RAG chat app with Azure OpenAI and Azure AI Search (Python)” sample to build the project, using Azure OpenAI, Azure AI Search, and Azure Document Intelligence to power the experience. The goal was to make over 2,000 JFK-related documents searchable and interactive using a natural language interface.
The Ingestion Phase and Initial Costs
The first hurdle was document ingestion. It cost approximately $687 to upload and process 2,182 JFK documents into Azure Blob Storage and pipe them through the necessary services. This one-time charge primarily came from Azure Applied AI Services — specifically Azure Document Intelligence, which parses and enriches the raw data for indexing.
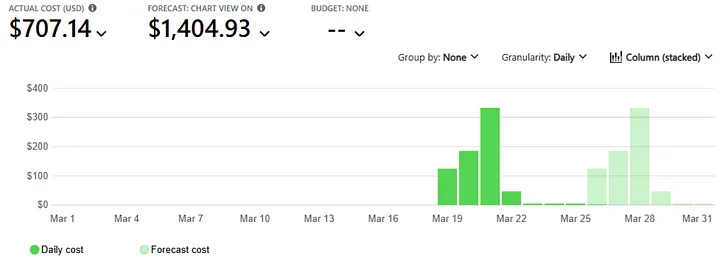
While the Azure cost forecast may suggest a dire financial picture, that forecast is misleading — it includes the ingestion spike, which doesn’t reflect the steady-state behavior of the system.
Settling into a Daily Burn Rate
Now that the initial work is done, daily operations have leveled out to about $5.20 per day.
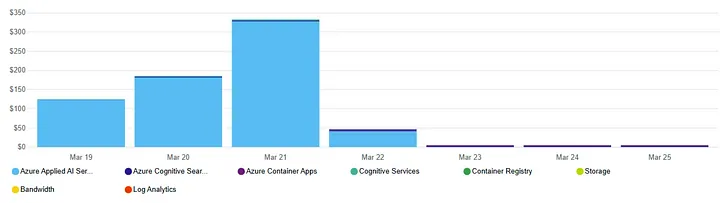
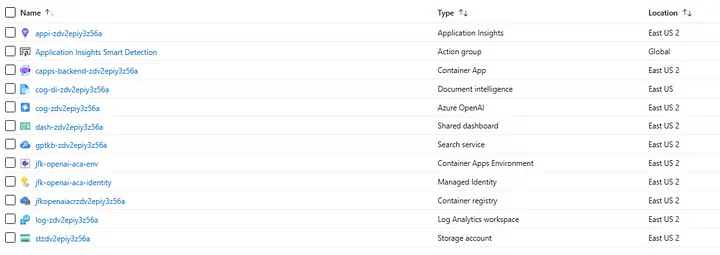
You can see that during the data ingestion, the lionshare of the cost came from “Azure Applied AI Services”. What is that $5.20 a day paying for? Well the Resource Group has the following stuff.
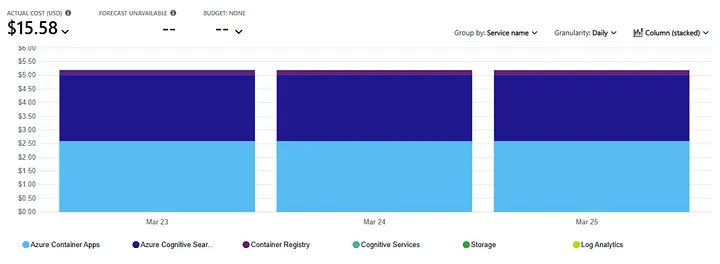
That ongoing cost boils down to two main buckets:
- The Azure Container App, which hosts the chat interface and handles request routing.
- Azure AI Search, which indexes and retrieves relevant content for the OpenAI model to summarize and respond with.
These components are what’s quietly ticking away in the background. The system remains live for others to explore, and while I was initially concerned about runaway costs from user activity, that hasn’t materialized.
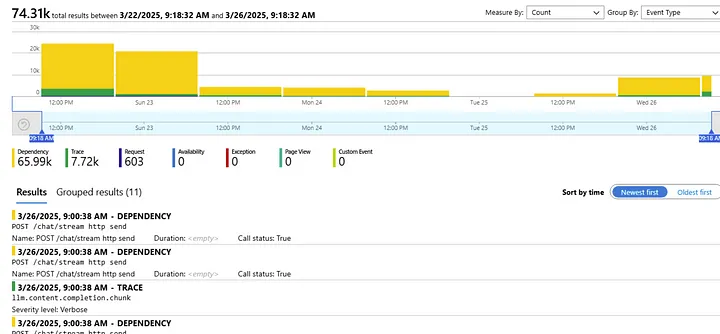
Over the past several days, there have been about 9,000 requests to the chat endpoint (POST /chat/stream http send). It’s been surprisingly quiet.
Performance and Model Frustrations
Despite the infrastructure holding up well, the user experience has been underwhelming. The sample app defaults to ChatGPT 3.5 Turbo, and after getting used to more capable models like GPT-4o and GPT-4-turbo (1o), 3.5 feels sluggish and simplistic by comparison — like switching from an IMAX movie to basic cable. The AI search responses lack the depth and accuracy I expect from a modern LLM-driven app.
That shortfall likely isn’t the fault of the RAG architecture itself. It’s more about the model tier. This is especially frustrating after investing heavily in ingestion and setup, only to find that the core AI interaction — arguably the most visible part of the whole experience — doesn’t meet expectations.
What’s Next?
After spending that much to prep and process the documents, it feels premature to pull the plug without testing the environment under better conditions. Before shelving the project, I’m considering switching the app’s model to GPT-4-turbo or GPT-4o to see if the quality of the chat responses improves.
That change could provide a much fairer test of what Azure OpenAI and Azure AI Search can offer when paired with a top-tier model. If nothing else, it would help determine whether the architecture itself is worth iterating on — or whether this whole experiment was just a costly detour.
Conclusion
The “RAG chat app with Azure OpenAI and Azure AI Search (Python)” is a solid starting point, but the cost dynamics are nuanced. Initial ingestion can be expensive, especially with a large document corpus, but daily operational costs are manageable — so long as traffic stays moderate.
The real question is whether the default configuration can deliver a satisfying AI experience. Right now, it doesn’t. But with a few tweaks, it might. At this point, it’s less about cost and more about making sure the tech stack is set up to do justice to the data it’s been given.
You can still chat with the JFK files here.